GPU Benchmarking Study: Fibonacci Case Study
title: GPU Benchmarking Study: Fibonacci Case Study description: GPU-Accelerated Fibonacci Sequence Sorting with NVIDIA’s CUDA / C++ date: 2024-01-31
GPU Benchmarking Study: Fibonacci Case Study
Introduction
This project benchmarks CPU-based manual sorting algorithms against GPU-accelerated sorting using NVIDIA Thrust, using a generated Fibonacci sequence as the input dataset.
The workflow:
- Generate a Fibonacci sequence of length N
- Observe integer overflow behavior (negative values appear after exceeding
intrange) - Run manual CPU sorting algorithms:
- Bubble Sort
- Quick Sort
- Merge Sort
- Heap Sort
- Run GPU sorting algorithms using the Thrust library:
thrust::sortthrust::transform + thrust::sort
- Measure runtime and compare results
This study highlights how GPU parallelization can drastically reduce sorting time compared to traditional CPU execution.
What is CUDA?
CUDA (Compute Unified Device Architecture) is NVIDIA’s platform for GPU computing. It enables developers to write parallel code that runs on NVIDIA GPUs, accelerating workloads by executing many operations simultaneously.

Why C++ (instead of C)?
CUDA is implemented as an extension of C++, which makes it the natural choice for GPU programming. Using C++ allows the project to benefit from:
- richer syntax and modular design
- STL and template support
- interoperability with libraries like Thrust
- improved maintainability and readability
Project Setup
The Main Idea
- Generate Fibonacci values up to a given length N
- After some point, Fibonacci values overflow
intrange and become negative - Sort the generated sequence on the CPU and GPU using different methods
- Compare runtimes to evaluate performance differences
Where was this executed?
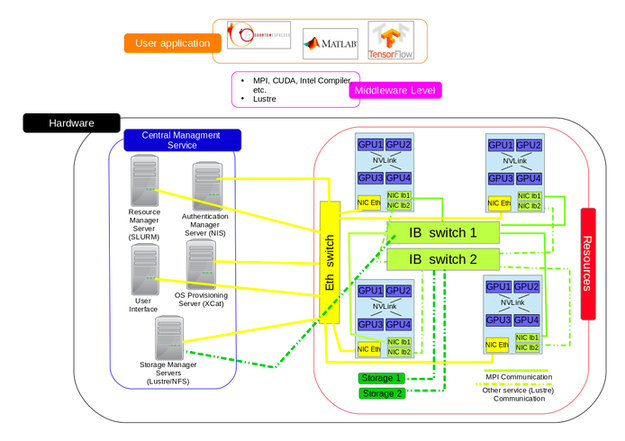
This project was executed on the IBISCO HPC Cluster
(Infrastructure for Big Data and Scientific Computing)
University of Naples Federico II.
IBISCO provides:
- 32 server nodes
- each node equipped with 4 GPUs
- GPUs connected via NVLink
- nodes connected via InfiniBand
Why negative Fibonacci numbers appear?
The Fibonacci sequence grows rapidly. When values exceed the maximum capacity of an int, an integer overflow occurs.
Example:
1134903170 + 1836311903 = 2971215073 // exceeds max signed int
After overflow, the stored value becomes negative:
... 1134903170 1836311903 -1323752223 ...
From that point onward, the sequence continues producing negative values.

How to Run
To execute the program, make sure these 3 files exist in the same directory:
1) Makefile
simpleKernel: simpleKernel.cu
nvcc -o simpleKernel simpleKernel.cu
clean:
rm simpleKernel
2) simpleKernel.cu
This file contains the CUDA C++ program:
- Fibonacci generation
- CPU sorting algorithms
- GPU sorting using Thrust
- runtime measurement
(Full code is available in the GitHub repository.)
3) simpleKernel.sh
Executor script (runs the code via Slurm on a GPU node):
#!/bin/bash
if [ $# -ne 1 ]
then
echo "Usage: $0 <NTHREADS>"
exit 1
fi
echo "Compile program"
make
echo
echo "Execute program"
srun -N 1 -n 1 --gpus-per-task=1 -p gpus --reservation=maintenance ./simpleKernel
echo
echo "Clear temporay file"
make clean
echo
Execution Example
cd CUDA/Fibonacci/
./simpleKernel.sh 2
Where 2 represents the number of threads (e.g., 2 / 4 / 8 / ...).
Runtime Results
Below is an example runtime benchmark with N = 1000:
~ Manual Sorting Algorithms :
Bubble Sort Time: 16.328 ms
Quick Sort Time: 11.699 ms
Merge Sort Time: 1.070 ms
Heap Sort Time: 0.771 ms
~ Sorting by Thrust library :
Thrust Sort Time: 0.081 ms
~ Thrust Sorting Algorithm :
Thrust Sort + Transformation Time: 0.033 ms
✅ CPU manual sorting takes up to 16.3 ms
⚡ GPU Thrust sorting takes as little as 0.033 ms
Worth noting:
Manual sorting algorithms run on the CPU, while Thrust sorting is executed on the GPU, leveraging parallel processing.
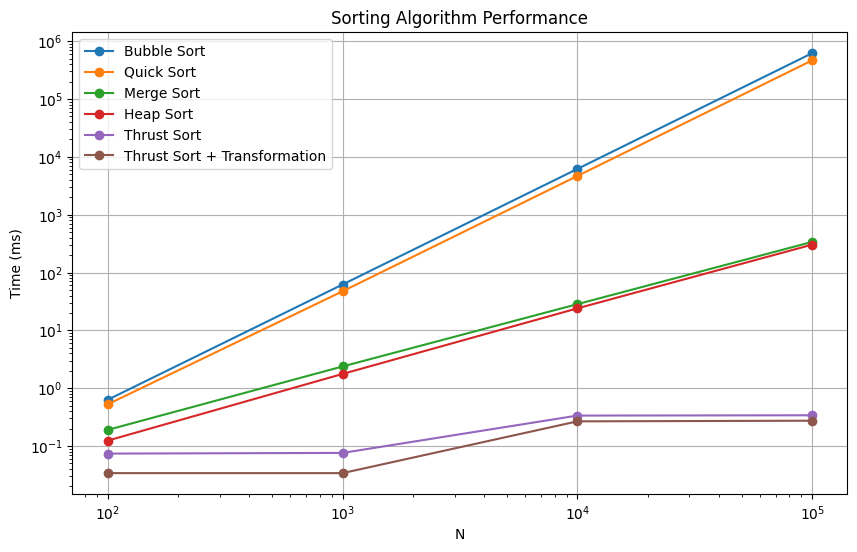
Scaling Test
I ran the benchmark for multiple Fibonacci sizes:
- N = 100
- N = 1000
- N = 10000
- N = 100000
Conclusion
This benchmarking study clearly demonstrates the performance advantage of GPU-accelerated sorting.
- Manual CPU sorting methods (Bubble / Quick / Merge / Heap) require significantly more time
- GPU sorting using Thrust is dramatically faster due to parallel computation
- Applying a simple transformation step prior to sorting (
thrust::transform) further improves speed
Overall, leveraging CUDA and Thrust for sorting tasks enables substantial runtime improvements, especially as dataset size grows.
Collaboration
Developed in collaboration with
Stefano Acierno
Source Code and Resources
Makefile
https://github.com/pouyasattari/Cuda-GPU-fibonacci-Parallel-Programming-project/blob/main/Makefile
simpleKernel.cu
https://github.com/pouyasattari/Cuda-GPU-fibonacci-Parallel-Programming-project/blob/main/simpleKernel.cu
simpleKernel.sh
https://github.com/pouyasattari/Cuda-GPU-fibonacci-Parallel-Programming-project/blob/main/simpleKernel.sh
GitHub Repository
https://github.com/pouyasattari/Cuda-GPU-fibonacci-Parallel-Programming-project/tree/main
Thank you for taking the time to read this article — your feedback is warmly welcomed.
Furthermore, I would be happy to assist you in solving a puzzle during your data journey.
pouya [at] sattari [dot] org