Legal Chatbot: Divorce and Inheritance Italy Laws – HF Space
title: Legal Chatbot: Divorce and Inheritance Italy Laws – HF Space description: LLM + NLP: Chatbot using LangChain with OpenAI’s API to process legal documents date: 2024-02-01
Legal Chatbot: Divorce and Inheritance Italy Laws – HF Space
LLM + NLP: Chatbot using LangChain with OpenAI’s API to process legal documents
Introduction
The rise of Large Language Models (LLMs) is transforming how people access legal information online — especially in specific legal domains and within a particular jurisdiction. This project demonstrates how to build a legal chatbot focused on Italian divorce and inheritance law, making legal guidance easier to understand and more accessible through a clean and interactive interface.
This chatbot is built using Python, Streamlit, and LangChain, powered by OpenAI’s LLMs (initially gpt-3.5-turbo, later upgraded to gpt-4o-mini). It processes complex legal documents into structured, searchable knowledge and generates context-aware answers grounded directly in the source texts.
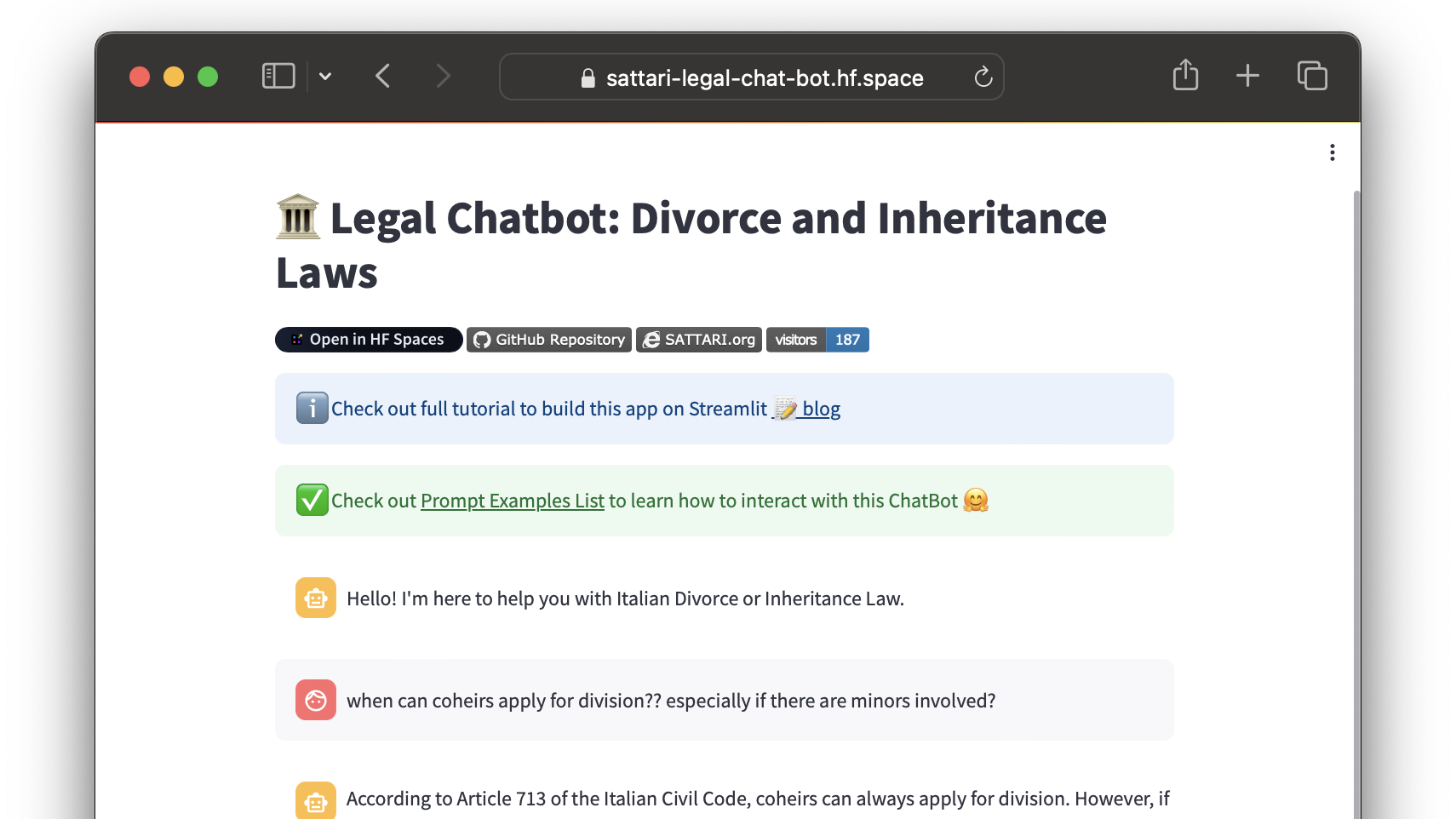
👉 You can try the app here:
Legal Chatbot on HuggingFace Spaces
How the Legal Bot Operates (RAG Workflow)
This chatbot follows a Retrieval-Augmented Generation (RAG) architecture, combining document search + LLM response generation.
Step 1: Ingestion (Indexing)
The legal documents are prepared into a searchable index (vector store):
- Load the legal documents
- Split them into smaller chunks (articles / sections)
- Generate embeddings for each chunk
- Store embeddings into a vector database (ChromaDB)
Step 2: Generation (Answering)
When a user asks a question:
- The query is embedded
- Similar chunks are retrieved from the vector database
- The LLM receives: question + retrieved context
- The chatbot generates a grounded answer based on the documents
App Overview
When the app launches, LangChain processes two legal documents:
DIVISION OF ASSETS AFTER DIVORCE.txtINHERITANCE.txt
They are stored inside the project’s ./data/ folder, then indexed into a persistent ChromaDB directory:
./docs/chroma
When the user asks a question, the bot retrieves the most relevant legal content and answers with context-aware responses.

Deployment via HuggingFace Spaces
This project is deployed on HuggingFace Spaces using the Streamlit stack, making it easy to share publicly and run without local setup.
A key reason for choosing HuggingFace Spaces over GitHub Pages was handling large files — particularly ChromaDB persistence folders — without Git LFS complexity.
- App: HF Space
- Code: HF Repo File
- ✅ Note: Code was updated in October 2024 to upgrade the model to
gpt-4o-mini.

Implementation Highlights
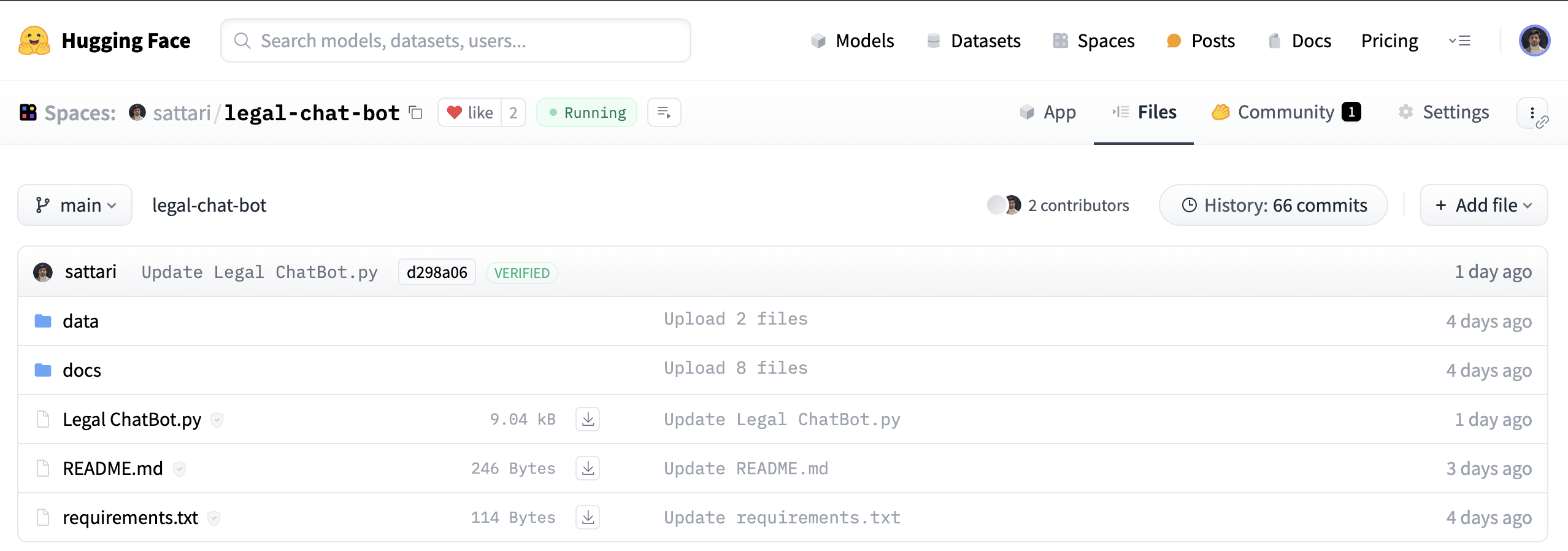
File Structure
This application follows HuggingFace + Streamlit standards:
README.md→ Space configrequirements.txt→ DependenciesLegalBot.py→ Main chatbot scriptdata/→ Two legal documentsdocs/chroma/→ Persistent vector database
Core Features
✅ Legal document chunking (law_content_splitter)
✅ Embeddings + Vector store (ChromaDB)
✅ RetrievalQA pipeline for grounded answers
✅ Prompt engineering for domain-specific behavior
✅ Tools routing between Divorce vs Inheritance
✅ Memory (ConversationBufferMemory) for conversational continuity
✅ Greeting detection for a human-friendly UX
✅ Streamlit UI with message history and prompt examples
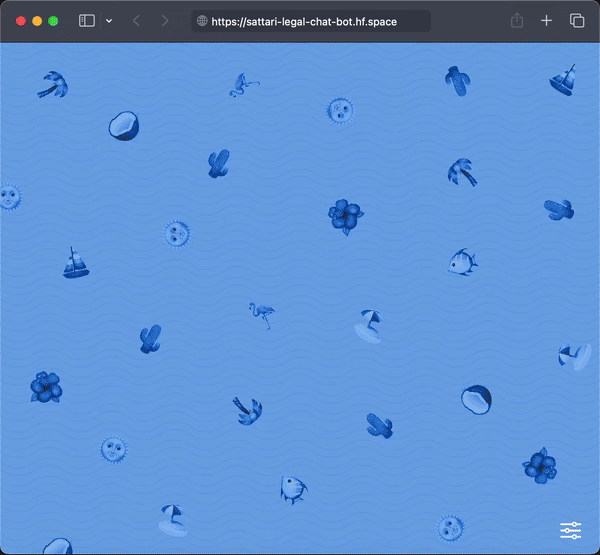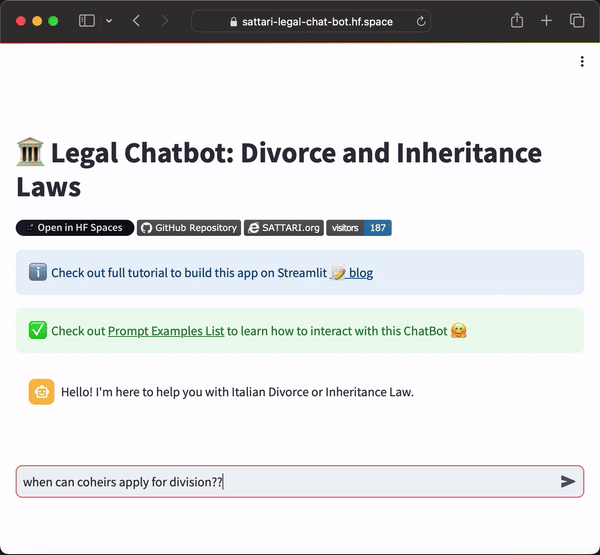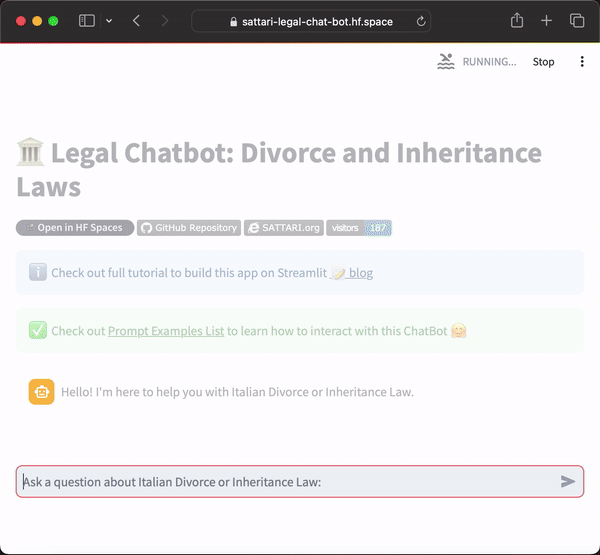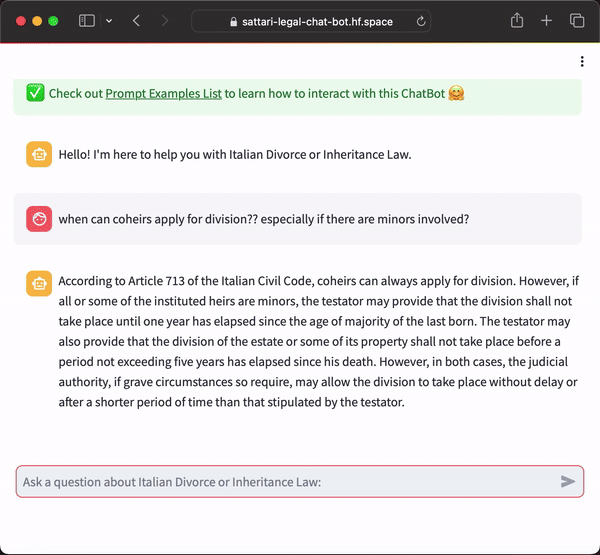
Example Interaction
Question:
“When can coheirs apply for division, especially if there are minors involved?”
Deploying Your Own Version
To deploy a similar chatbot on HuggingFace Spaces:
- Create a new Space on HuggingFace
- Select Streamlit as SDK
- Make it public
- Upload your files (
app.pyorLegalBot.py,requirements.txt, docs, vector store) - Add your OpenAI API key in HF Secrets
- Click the App tab and run 🎉
Wrapping Up
This project demonstrates how modern NLP frameworks like LangChain, paired with OpenAI models, can transform large legal texts into an interactive assistant that provides fast, structured, and contextual legal guidance.
While the chatbot is designed for informational support, it does not replace a qualified lawyer — especially for nuanced case-specific decisions.
Source Codes & Resources
- HuggingFace Space
- LegalBot.py – Main Code
- README.md
- requirements.txt
- docs/ – ChromaDB directory
- data/ – Legal text corpus
Thank you for taking the time to read this article; your valuable feedback is warmly welcomed.
Furthermore, I would be happy to assist you in solving a puzzle in your Data journey.
pouya [at] sattari [dot] org